In this post, I am going to walk you through my creation of a neural network to predict oscar winners. This project was completed as part of my Machine Learning course at Georgia Tech.
getting the dataset
For the project, we decided to take pieces of various open-source datasets. The IMDB Movies Dataset on Kaggle was used for collecting data regarding IMDB rating, number of ratings, and the runtime of the movie. The Movie Database API was used to collect data regarding budget, earnings, and the release data of the movie. Lastly, we used Kaggle’s Movies Dataset to get the genre of every movie.
Our features included runtime, IMDB score, genres of the movie, earnings, and release month.
Since the genres were given to us as strings, we assigned each genre a unique number so that it could be accessible for the neural network.

The table above is a sample of the dataset we used.
Neural network architecture
The neural network was developed using TensorFlow in python. The architecture that worked best for the prediction was the following:
- Flatten Layer
- Dense Layer of size 7 with ReLU activation
- Dense Layer of size 7 with ReLU activation
- Output Dense Layer of size 1 with Sigmoid activation
Code:
model = keras.Sequential([
keras.layers.Flatten(input_shape=(7,)),
keras.layers.Dense(7, activation=tf.nn.relu),
keras.layers.Dense(7, activation=tf.nn.relu),
#keras.layers.Dense(2, activation=tf.nn.relu),
keras.layers.Dense(1, activation=tf.nn.sigmoid),
])
Results
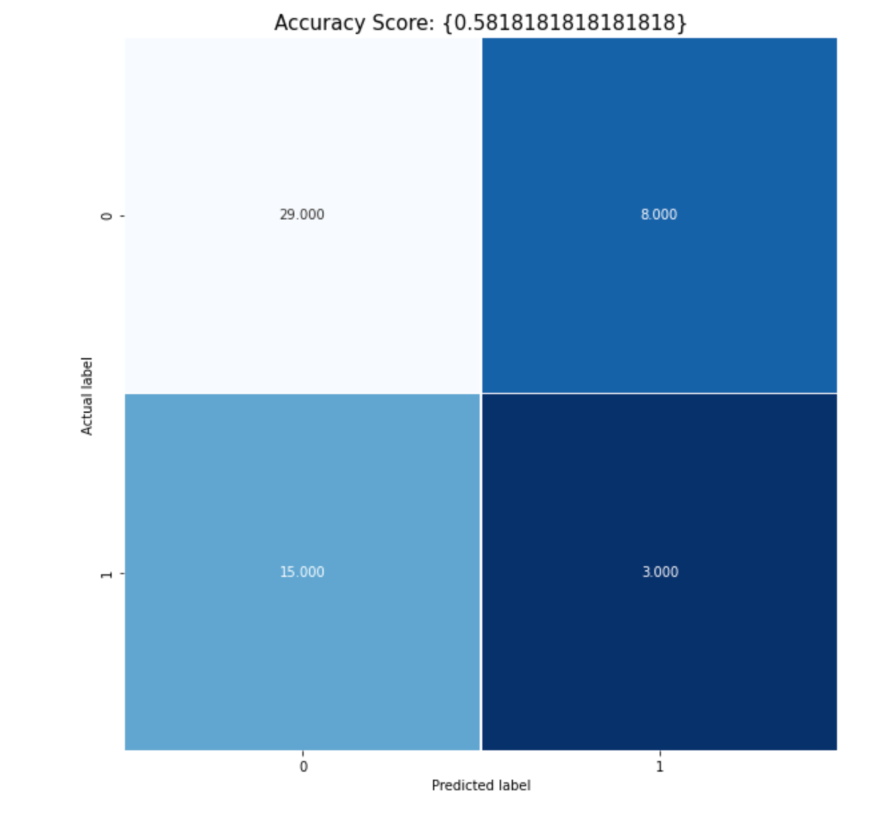
The overall accuracy of the neural network was 58.18%. However, we see that only 16.67% of the actual winners were predicted as winners. The neural network only works slightly better than random chance. We believe that the features we chose were not the best indicators of which movie would win an Oscar award. Therefore, to improve the models, a new feature set could be used. Also, different architectures for the neural network may work better than the one we used.
